Dlaczego sztuczna inteligencja jest tak droga w 2026 r.? Prawdziwy koszt sztucznej inteligencji w chmurze
Anthropic właśnie wysłał model, który kosztuje pięćdziesiąt dolarów za milion zapisanych słów. Oto dlaczego pionierska sztuczna inteligencja jest tak droga i dlaczego sztuczna inteligencja, z której korzystasz na co dzień, nie musi kosztować ani centa.
Przedmowa
On June 9, 2026, Anthropic released the most capable AI model the public can buy. It is called Claude Fable 5, and the company priced it at fifty dollars per million tokens of output. A token is a small piece of a word. Fifty dollars buys you somewhere around 750,000 words of writing, which sounds like plenty until you meet a coding agent that burns through it in an afternoon.
That is the headline number behind every AI cost story right now. The frontier is getting more expensive, not cheaper.
It is also the small story.
The AI you actually touch every day is not a frontier coding model. It is the small, quiet stuff: turning your speech into text, reading an article back to you, tidying up a note before you send it. That kind of AI does not need a data center. It does not need a meter. And in 2026, it does not need to cost you anything at all.
So two questions are worth answering plainly. Why is AI expensive at all? And are you paying for AI that you could be getting for free? Both have clear answers, and the second one is the one most people miss.
Za co właściwie płacisz: żetony, w prostym języku angielskim
Cloud AI is sold by the token. A token is a chunk of text, roughly four characters, or about three quarters of a word. The word "expensive" is one token. The word "tokenization" is three. Every message you send and every reply you get is counted out in tokens, and you pay for both directions.
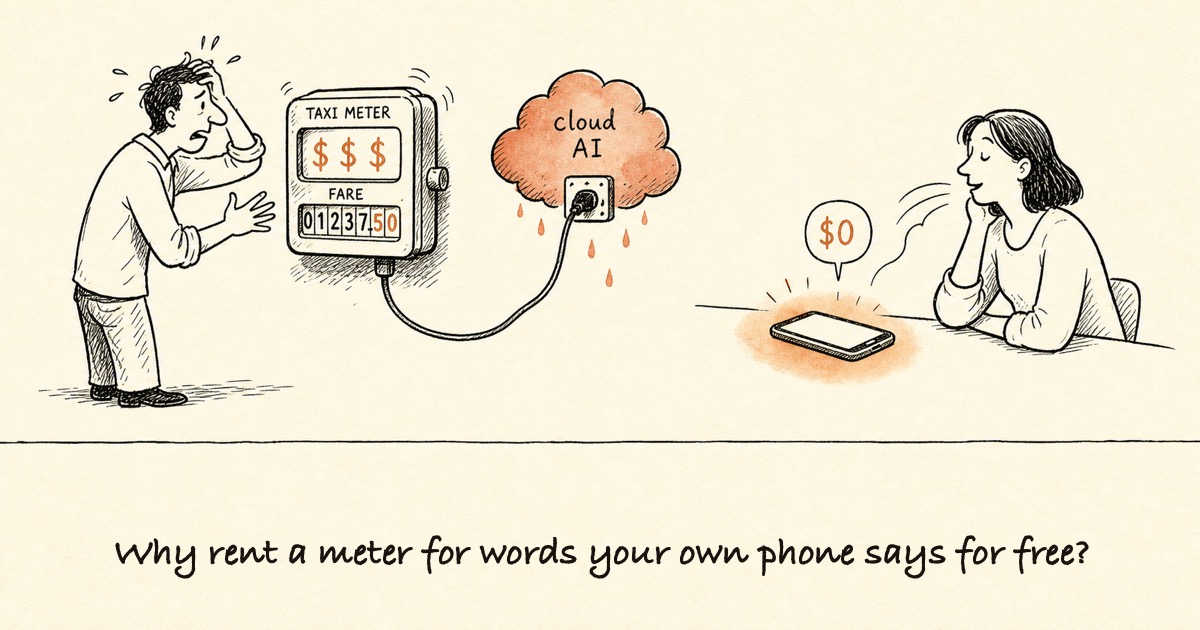
Think of it like a taxi meter. The meter does not care whether the ride was useful. It runs while the engine runs. Cloud AI works the same way: the meter runs on every word in and every word out, whether the answer was brilliant or useless.
Two details explain most of your bill.
Output costs more than input. Reading your words is cheap. Writing new ones is expensive, because the model has to do real work to generate each token. That is why Claude Fable 5 charges ten dollars to read a million tokens but fifty dollars to write a million. A chatty model that pads its answers is quietly running up your tab.
Long conversations get heavier as they go. Each new message usually carries the whole conversation back to the model as context. A chat that started cheap gets more expensive with every turn, because the model re-reads everything that came before. Multiply that across a team, or across an AI agent that calls the model ten times to finish one task, and the meter spins fast.
None of this is a scam. It is the honest cost of running very large models in someone else's data center. The question is whether you should be paying it for everything you do.
Dlaczego Frontier AI naprawdę kosztuje tak dużo
Before the case for the cheaper path, the case for the expensive one. Frontier AI is expensive for real reasons, and pretending otherwise would be dishonest.
The hardware is genuinely costly. The best models run on rooms full of specialized chips that cost tens of thousands of dollars each and draw enormous amounts of power. Renting that hardware by the hour is the single biggest line in any AI provider's budget. When you pay per token, you are renting a sliver of that room for a fraction of a second.
Building a model and running it are two different bills. Training a frontier model is a one-time, eye-watering expense: months of computation that can cost tens or hundreds of millions of dollars before a single customer touches it. Then comes the ongoing cost of answering every question, which is smaller per request but never stops. For a popular model, the second bill dwarfs the first over time.
Agents multiply everything. The big shift in 2026 is that AI no longer answers one question and stops. It works in long chains, calling the model again and again to research, plan, write, check its own work, and try again. An agent that makes ten calls to finish a job costs ten times what a single question would. Anthropic's own data shows token use exploding precisely because these agentic workflows became normal.
That is what the new models are built for. Claude Mythos 5, the restricted sibling of the public Fable 5, is the strongest model anyone has tested at finding and exploiting flaws in software. Anthropic and around fifty partners used a preview of it to discover more than ten thousand serious security holes in the world's most important software, through a program called Project Glasswing. That is genuinely hard, genuinely valuable work, and it genuinely costs money to run.
Część, której nikt ci nie mówi: prawdopodobnie przepłacasz
Here is the turn. Most of what ordinary people use AI for is not hard. It is small, repetitive, and well understood.
Turning speech into text is a solved problem. Reading text aloud in a natural voice is a solved problem. Cleaning up a rough note, summarizing a paragraph, drafting a quick reply: these ran acceptably on small models years ago. They do not need the most powerful model on earth, and they certainly do not need to phone a data center every time.
Yet that is exactly how most apps do it. Your voice gets recorded, sent across the internet, processed on rented hardware, billed by the token, and sent back. You pay for that round trip in three currencies: money, time, and privacy. The money shows up as a subscription or a per-word fee. The time shows up as the half-second of lag while your words fly to a server and back. The privacy shows up as a copy of your voice sitting on a company's computer.
There is a simpler arrangement. The model can live on your own device.
Everyday AI in the cloud
A meter on the small stuff
Every dictated sentence, every read-aloud, every tidy-up is recorded, uploaded, billed by the token, and sent back. You pay in money, in lag, and in a copy of your voice you do not control. The bill grows with every word.
Everyday AI on your device
No meter at all
The model runs on the phone or laptop you already own. Nothing uploads. Nothing is billed by the token. The thousandth sentence costs exactly what the first one did, which is nothing, and your words never leave your hands.
Sztuczna inteligencja na urządzeniu: wersja bez licznika
On-device AI, sometimes called local AI, means the model runs on the hardware in your pocket or on your desk instead of in a distant data center. Your phone and your laptop are now fast enough to do this for everyday tasks. The model is downloaded once and then it just works.
The economics flip completely. In the cloud, every word costs a fraction of a cent, and those fractions add up forever. On your device, the work costs nothing extra once the model is installed. The first sentence and the millionth sentence cost the same: zero. There is no meter to run.
That single fact, no marginal cost, is why on-device AI keeps winning the moment your usage stops being occasional. But cost is only the first of three reasons it matters.
It is private. Your words are processed where you said them. Nothing travels to a server, so there is no copy of your voice to leak, subpoena, sell, or train on. Privacy stops being a promise in a policy document and becomes a fact of the architecture.
It works offline. A model on your device does not care about the wifi on the plane, the dead spot on the train, or the outage at the data center. Speak on the subway, in the woods, on a flight, and it keeps working.
It does not change underneath you. A cloud model can be updated, retired, rate-limited, or repriced at any time, and your workflow changes with it. The model on your device stays exactly as it is until you choose to update it. What worked yesterday works tomorrow.
The cheapest data to secure is the data you never send. If your words never leave the device, no price change, no policy update, and no breach can reach them.
The case for on-device AI
Głos to sztuczna inteligencja, z której wszyscy korzystają na co dzień
If you want one concrete example of AI that belongs on your device, voice is it. You use it constantly, it is simple enough to run locally, and it handles the most personal data you have: your actual words, in your actual voice.
This is the whole idea behind Yaps. Yaps is a voice assistant that runs its speech entirely on your own device. It turns talking into typed text in any app, reads text back to you in a natural voice, and transcribes recordings into clean notes, all without sending your audio anywhere. It works on Android, Mac, Windows, and Linux today, with iOS coming soon.
The loop is simple. Push the Yaps hotkey, talk the way you would talk to a person, and watch clean text land in whatever app you are using. On a Mac that hotkey is the Fn key. On the Yaps Android keyboard, it is a dedicated dictation button you reach with your thumb. There is no app to switch to, no overlay to chase, and no round trip to a server while you wait.
Push the Yaps hotkeyinstant
One key on a Mac, one thumb-button on Android. No app switch, no menu, no waiting.
Speak naturallyyour words
Talk at a normal pace. You speak around 150 words a minute, roughly three times faster than you type.
Your device does the workno upload
The speech runs on your own hardware. Nothing is recorded to a server, and nothing is billed by the token.
Clean text appears$0
Tidied, punctuated, and dropped into your email, your notes, your chat. The thousandth sentence costs the same as the first.
Because the model lives on your device, there is no per-word meter on your voice. Dictate a one-line reply or a two-thousand-word first draft, and the speech itself does not cost you a token either way. That is the difference between renting AI by the word and owning the part you use most.
To be straight about it: Yaps is not a magic wand that makes all AI free. It runs its core dictation, read-aloud, and transcription on your device at no per-word cost, which covers the everyday tasks above. It also offers optional cloud extras, such as premium cloud voices and a heavier cloud text cleanup, for people who want them. Those use the cloud and are part of the paid plan. The point is that you are never forced onto a meter for the basics. The everyday stuff stays on your device, free of token costs, by default.
Kiedy warto zapłacić za chmurę
On-device AI is the right default for everyday work. It is not the right tool for everything, and saying otherwise would be the same overselling this article is arguing against.
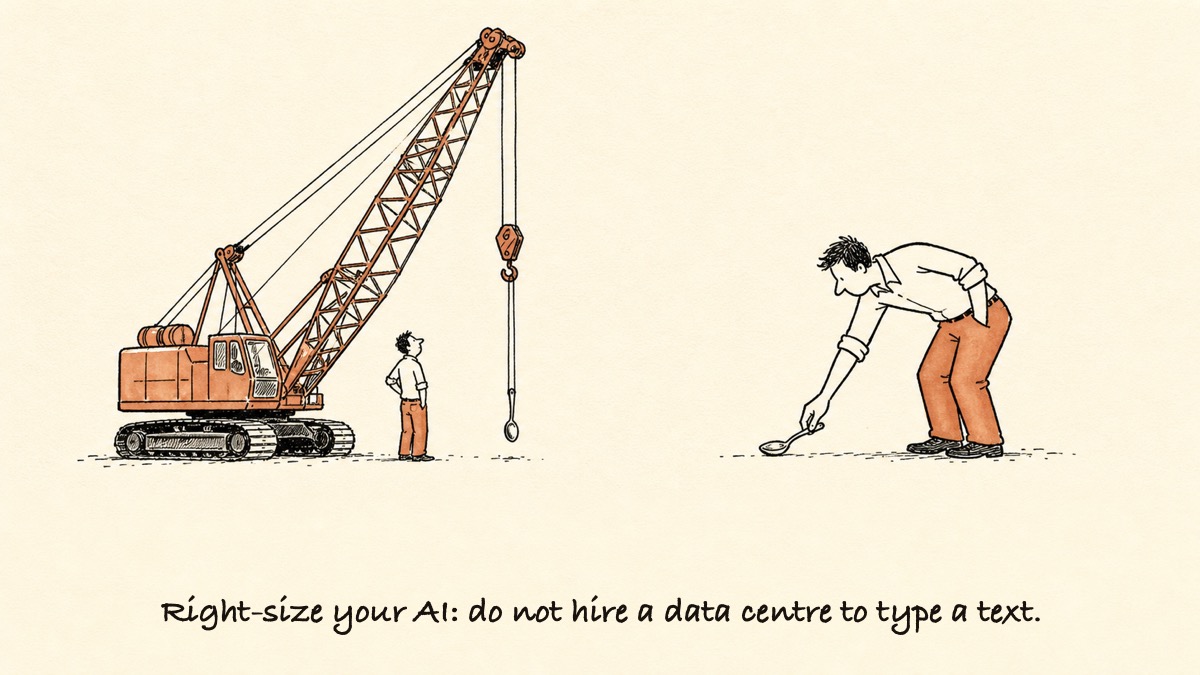
Some tasks genuinely need a frontier model in the cloud, and for those, paying by the token is money well spent. Deep research that reads across hundreds of web pages. An agent that rewrites code across an entire project. The kind of multi-step security work Claude Mythos was built for. These are hard problems where the most powerful model earns its price, and your laptop is not going to match it.
The trick is to match the tool to the task instead of routing everything through the most expensive option you have. Here is the simple version.
| What you want to do | On-device (free, private) | Cloud frontier (metered) |
|---|---|---|
| Turn speech into text | Best fit | Overkill |
| Read text aloud | Best fit | Overkill |
| Transcribe a recording | Best fit | Optional |
| Tidy up a rough note | Handles it | Optional |
| Deep research across the web | Limited | Best fit |
| Agentic coding across a project | Limited | Best fit |
| Find security flaws in software | No | Best fit |
Read that table top to bottom and a pattern jumps out. Everything you do many times a day sits in the free column. Everything in the metered column is something you do occasionally, if at all. Most people have the ratio backwards, paying cloud prices for the daily tasks and rarely touching the frontier work that would actually justify the bill.
Drugi powód, dla którego liczy się teraz urządzenie
The Claude Mythos launch carried a second piece of news that is easy to miss in the pricing talk. The same week Anthropic shipped the most powerful model ever, it also warned that AI is becoming dangerous enough to demand new caution. Mythos is the best system anyone has built at finding and exploiting weaknesses in software. That capability secures critical systems in the right hands. In the wrong hands, it does the opposite.
You do not need to follow the security debate to take the practical lesson. As AI gets better at probing systems and data, the safest data is the data that was never sent anywhere in the first place. A recording sitting on a company server is a target. A sentence that was processed on your own phone and never uploaded is not a target, because it does not exist anywhere to be reached.

That is the deeper reason Yaps keeps speech on the device. It started as a privacy decision, not a cost decision. The cost saving turned out to be the bonus that came with building it the private way. For more on how that architecture protects your data, see our guide to protecting your voice data and the case for a privacy-first voice assistant.
Jak dopasować rozmiar sztucznej inteligencji
Pull the whole argument into one rule and it is short. Pay for frontier AI when the task is genuinely hard. Use free, on-device AI for the everyday tasks that are not.
The hard tasks are rare and worth the meter: deep research, agentic coding, the heaviest reasoning. The everyday tasks are constant and should not cost you a cent: turning speech into text, reading things aloud, transcribing a recording, cleaning up a note. Those run perfectly well on the device you already own.
For that everyday layer, and for voice in particular, Yaps is the place to start. It puts dictation, read-aloud, and transcription on your own device, free of any per-word token bill, private by design, and working whether or not you have signal. If your needs run to occasional frontier work on top of that, reach for a cloud model like Claude Fable 5 for those specific jobs and pay the meter only when it earns its keep.
The frontier will keep getting more powerful and, at the top end, more expensive. That is fine. It is building things that are worth the price. Just do not let it bill you for the small, daily AI that your own phone can do for free. Right-size the tool to the task, and the expensive model becomes something you rent on purpose rather than a meter that runs by default.
Download Yaps and move your everyday AI off the meter. Push the hotkey, talk, and let the cloud bill someone else.
Często zadawane pytania
Why is AI so expensive?
Frontier AI is expensive because the best models run on rooms full of specialized chips that cost tens of thousands of dollars each and draw huge amounts of power, all rented by the hour. You pay for a sliver of that hardware every time the model reads or writes a word. Costs climb further in 2026 because AI agents now call the model many times to finish a single task, so the meter runs faster than it used to. The everyday AI most people use, like voice typing, does not need that hardware and can run for free on your own device.
How much does Claude Fable 5 cost?
Claude Fable 5 costs ten dollars per million input tokens (the text you send) and fifty dollars per million output tokens (the text it writes back). That is roughly twice the per-token price of Claude Opus 4.8 and about three times the price of Claude Sonnet 4.6. Batch processing for non-urgent jobs cuts both rates in half, and reusing a cached prompt drops the input rate to one dollar per million tokens.
Can I use Claude Mythos, and what does it cost?
Most people cannot use Claude Mythos 5 directly. It is restricted to a small group of vetted partners through Anthropic's Project Glasswing, aimed at securing critical software. Its list price matches Fable 5 at ten dollars input and fifty dollars output per million tokens, but access is limited rather than open. Claude Fable 5 is the public, guardrailed version that the rest of us can actually buy.
What is a token in AI?
A token is a small chunk of text that an AI model reads and writes, usually about four characters or three quarters of a word. AI providers count your usage in tokens and bill you for both the tokens you send and the tokens the model generates. As a rough guide, one million tokens is around 750,000 words. On-device tools like Yaps do not bill by the token at all, because the work happens on your own hardware.
Why do output tokens cost more than input tokens?
Output tokens cost more because generating new text is harder work than reading existing text. When the model reads your message, it processes words that already exist. When it writes a reply, it has to produce each word from scratch, which takes more computation. That is why Claude Fable 5 charges fifty dollars to write a million tokens but only ten dollars to read them. A model that rambles runs up your bill faster than a concise one.
How much does AI cost per month for a regular person?
For a regular person, most consumer AI is sold as a flat subscription, often somewhere between ten and thirty dollars a month per app, rather than metered by the token. The metered, per-token pricing mostly affects developers and businesses, where Ramp's 2026 data put the median company spend at around 2,246 dollars a month and the average far higher. The cheapest path for everyday tasks is on-device AI, which has no monthly token bill at all once it is installed.
Is on-device AI actually free?
The processing is free in the sense that running the model on your own device adds no per-word cost, no matter how much you use it. You may still pay for the app itself, since building and maintaining good software is not free, but you are not paying a meter that grows with every sentence. Yaps, for example, runs core dictation, read-aloud, and transcription on-device with no token charge, and keeps optional cloud extras on a separate paid plan.
Is on-device AI as good as cloud AI?
For everyday tasks, on-device AI is now good enough that most people cannot tell the difference. Turning speech into text, reading text aloud, and transcribing recordings all run accurately on modern phones and laptops. For the hardest tasks, like deep research or rewriting a whole codebase, frontier cloud models are still clearly ahead. The smart approach is to use on-device AI for the daily work and reach for the cloud only when the job genuinely needs it.
Does voice typing or dictation use tokens?
It depends on where the speech is processed. Cloud-based dictation tools send your audio to a server, process it there, and can bill by the token or by subscription. On-device dictation, like Yaps, processes your speech on your own hardware, so there are no tokens and no per-word charge. On-device also means your voice never leaves the device, which is faster and more private.
Is Yaps free?
Yaps has a 7-day free trial, and a paid plan after that for continued use and cloud-based extras. The core dictation, read-aloud, and transcription run on-device with no per-token bill, which is the part that replaces metered cloud AI for everyday tasks. You can start with the free trial and only continue if you want the on-device voice layer plus the optional cloud features.
Will AI get cheaper over time?
The cheapest and mid-range models keep getting cheaper as the technology improves, and a task that cost real money in 2025 often costs a fraction of that today. The frontier, however, is moving the other way: the most capable new models, like Claude Fable 5, are priced higher than the flagships before them, because they do more and cost more to run. So AI is splitting into a cheap, commoditized bottom and an expensive, premium top. On-device AI sits at the free end of that split for the tasks it can handle.
Is on-device AI more private than the cloud?
Yes, because on-device AI processes your data where it was created and never sends it anywhere. There is no upload, so there is no copy of your voice or text sitting on a company server to be breached, subpoenaed, sold, or used for training. Cloud AI, by contrast, has to receive your data to process it, which means a copy exists outside your control. For sensitive material like your own voice, on-device is private by design rather than by promise.
What can Claude Mythos actually build?
Claude Mythos 5 is built for the hardest agentic and security work: finding and fixing flaws in software, multi-step software engineering, and deep technical research. Anthropic ranks it as the strongest model anywhere at discovering software vulnerabilities, and partners used a preview to find more than ten thousand serious ones. It is a specialist tool for difficult, high-stakes problems, not the kind of thing you would use to dictate an email. For that, a small on-device model is the better and cheaper fit.
What is the cheapest way to use AI in 2026?
The cheapest way to use AI in 2026 is to run it on your own device for everything that does not require a frontier model. On-device tools handle voice typing, read-aloud, transcription, and note cleanup with no per-word cost, no subscription meter, and no data leaving your hardware. Save the paid cloud models for the occasional hard task that genuinely needs them. For the everyday voice layer, an on-device app like Yaps removes the meter entirely.